Benchmarking
🚧 Under construction!
In this section you will find information on how to run performance testing experiments on DeepNLPF. To proceed, we consider that you have already installed DeepNLPF and the chosen plugins, as well as, it is expected that you already know how to use DeepNLPF. Otherwise look at this before.
Overview
The main objective here are:
- Check what is the computational cost (Runtime) of third-party NLP tools that run sequentially?
- Check if the parallelism strategy proposed by DeepNLPF optimizes the processing time (Runtime)?
Variables analyzed:
✅ CPU Runtime
❌ RAM memory usage
❌ Swap memory usage
❌ Number process
❌ Number threads
Dataset
The dataset used in this evaluation was SemEval 2010. From this dataset, 8000 sentences were extracted into a text file. From there, three files were generated, the first with 1000 sentences denominated (small dataset), the second with 4000 sentences (average datset) and the third remains with 8000 sentences (large dataset).
Statistic
SemEval Dataset
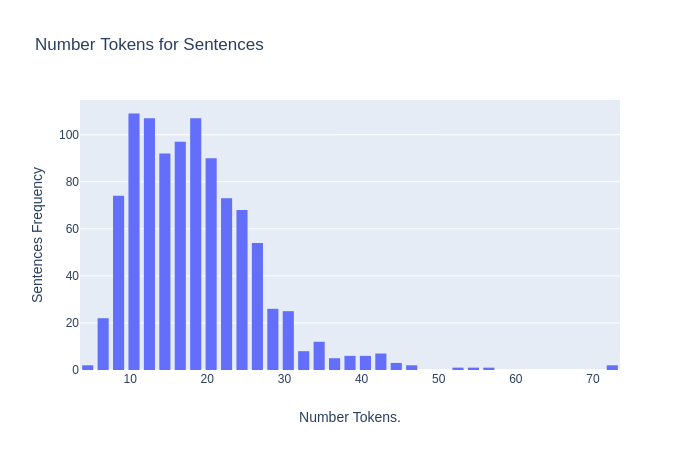
Total Sentences extracted: 8000
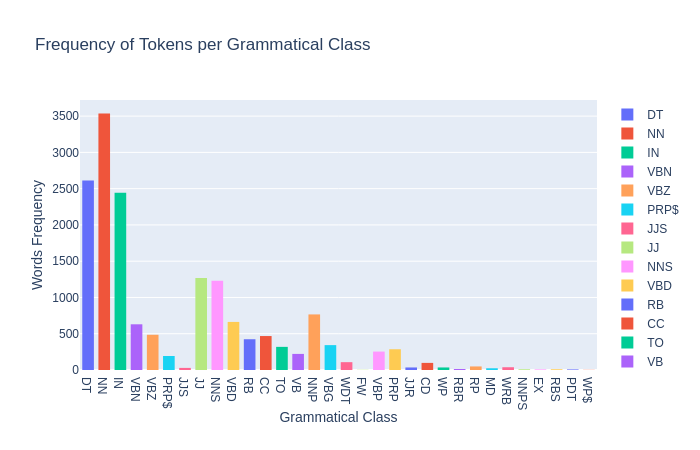
Total Tokens: 135,886
Min. Sentence Size: 4 tokens
Max Sentence Size: 95 tokens
Average Sentence Size: 17 tokens
Computer Config
To carry out the experiments, a notebook with an Intel Core i5 2.3GHz x 4 processor, 16GB of DDR3 RAM was used, Linux Ubuntu 19.04 operating system with 120GB SSD.
Stude Profile
To carry out this task it will be necessary to do the study of Profiling. Is a technique that allows you to identify the most resource-intensive points in an application. That is, a dynamic analysis that measures the program's execution time and everything that composes it. This means measuring the time spent in each of its functions. Providing data on where your program is spending and what area may be worth optimizing.
The experiments are performed from a Python Wrapper using cProfile, a Python module commonly used in Profiling analysis, which is a dynamic analysis that measures the program's execution time and everything that composes it.
SnakeViz
To view the results, the SnakeViz tool was used, a graphic viewer for the output of the cProfile module. The SnakeViz Tool provides an interface with interactive graphics, allowing you to navigate the processes when selected, thus, monitoring in depth which blocks of code (loops, functions, etc.) consume the most processing time. It is also possible to view a complete list of each process, functions performed, with their respective execution times and other more comprehensive information.
Experiments
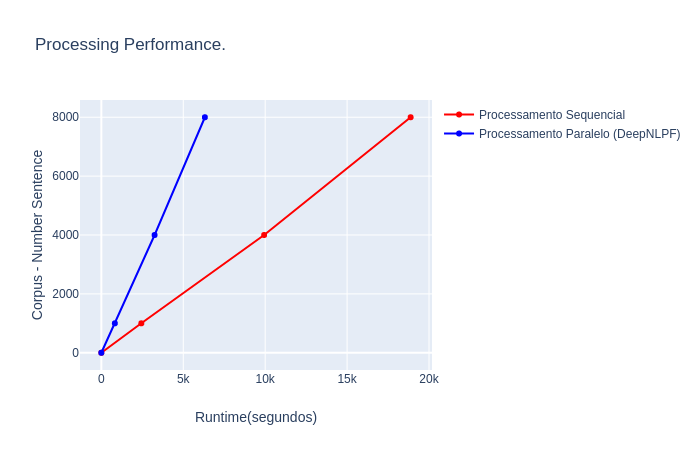
The experiments were carried out with the objective of evaluating the performance time of the third party NLP tools, considered here individually and, later, to compare the processing times when these same tools are processed (instantiated) from DeepNLPF. Therefore, the aim is to experimentally validate whether the parallel processing strategy employed by DeepNLPF really brings a significant performance improvement.
Experiment 1
Individual processing of selected NLP tools, just for analysis, lexicon.
- Stanford CoreNLP - Pipeline: tokenization, pos, lemma, ner, truecase.
- Spacy - Pipeline: pos, tag, shape, label, is_alpha, is_title, like_num.
- CogComp - Pipeline: ner ontonotes.
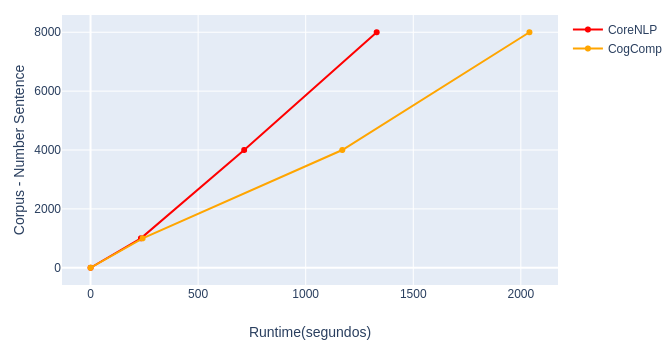
Individual processing of selected NLP tools, just for analysis, sintatic.
- Stanford CoreNLP - Pipeline: parse, depparse, dcoref.
- CogComp - Pipeline: shallow parse.
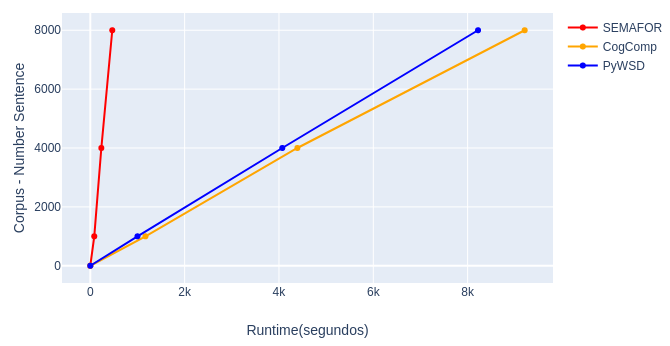
Individual processing of selected NLP tools, just for analysis, semantic.
- SEMAFOR - Pipeline: frame parsing semantic.
- CogComp - Pipeline: SRL Nom, SRL VerbeSRL Prep.
- PyWSD - Pipeline: WSD.
Experiment 2
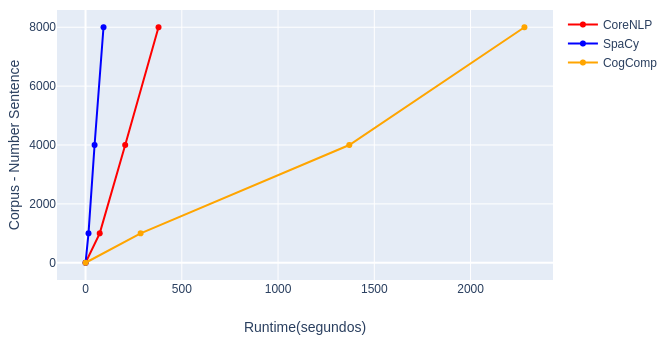
Individual processing of selected NLP tools, complete pipeline execution.
| Tools | Pipeline | Dataset 1 | Dataset 2 | Dataset 3 |
|---|---|---|---|---|
| Stanford CoreNLP | tokenize, ssplit, pos, lemma, ner, parse, depparse, truecase, dcoref | 270 | 775 | 1630 |
| SpaCy | pos, tag, shape, label, is_alpha, is_title, like_num | 12.3 | 46.3 | 91.2 |
| SEMAFOR | frame parsing semantic | 87.3 | 243 | 448 |
| CogCompNLP | srl nom, srl verb, srl prep, shallow parse, ner ontonotes | 1050 | 5110 | 9350 |
| PyWSD | wsd | 1020 | 3760 | 7360 |
| Runtime | 2439.6 | 9935.3 (+40,726%) | 18879.2 (+77,386%) |
Experiment 3
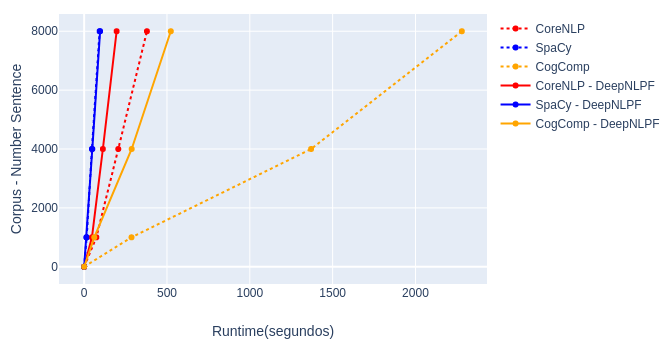
DeepNLPF, parallel processing of NLP tools, execution, lexical pipeline.
- Stanford CoreNLP: tokenization, pos, lemmaener.
- Spacy: pos, tag, shape, label, is_alpha, is_title, like_num.
- CogComp: ner, ontonotes.
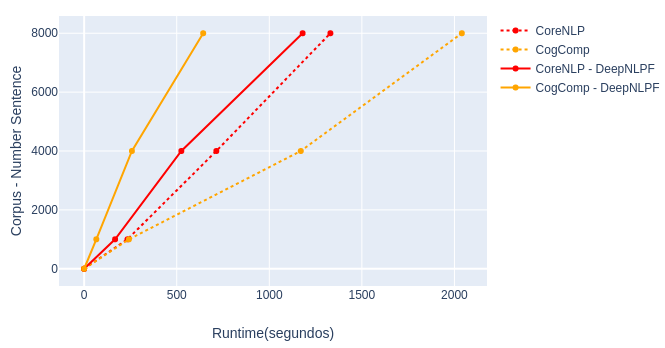
DeepNLPF, parallel processing of NLP tools, execution, sintatic pipeline.
- Stanford CoreNLP: parse, deppars, edcoref.
- CogComp:shallow parse.
DeepNLPF, parallel processing of NLP tools, execution, semantic pipeline.
- SEMAFOR: frame parsing semantic.
- CogComp: SRL Nom, SRL VerbeSRL Prep.
- PyWSD: wsd.
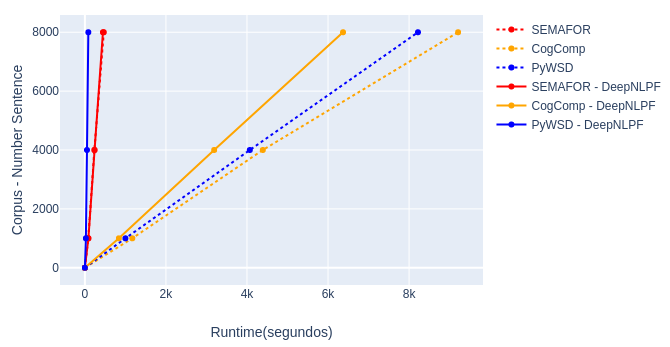
Experiment 4
Execution time of the complete pipeline of third-party NLP tools executed in a standard (sequential) way compared when executed from DeepNLPF.